http://technet.microsoft.com/en-us/library/ms174205%28v=sql.100%29.aspx
Powershell
Getting Started with SQL Server Powershell - http://www.allaboutmssql.com/2013/03/getting-started-with-sql-server.html
Handling strings using Powershell commands - http://www.allaboutmssql.com/2013/03/handling-strings-using-powershell.html
Executing Powershell commands using SSIS - http://www.allaboutmssql.com/2013/03/executing-powershell-commands-using-ssis.html
Reading XML file using Powershell - http://www.allaboutmssql.com/2013/03/reading-xml-file-using-powershell.html
Handling files using Powershell - http://www.allaboutmssql.com/2013/03/handling-files-using-powershell.html
Powershell - Create Database,Table and Storedprocedure using SMO - http://www.allaboutmssql.com/2013/03/powershell-create-databasetable-and.html
Powershell Command to get status of SQL Server services - http://www.allaboutmssql.com/2013/03/powershell-command-to-get-status-of-sql.html
Using Powershell commands inside SQL Agent Jobs - http://www.allaboutmssql.com/2013/03/using-powershell-commands-inside-sql.html
Execute Powershell Commands inside StoredProcedure - http://www.allaboutmssql.com/2013/03/executing-powershell-commands-inside.html
Handling strings using Powershell commands - http://www.allaboutmssql.com/2013/03/handling-strings-using-powershell.html
Executing Powershell commands using SSIS - http://www.allaboutmssql.com/2013/03/executing-powershell-commands-using-ssis.html
Reading XML file using Powershell - http://www.allaboutmssql.com/2013/03/reading-xml-file-using-powershell.html
Handling files using Powershell - http://www.allaboutmssql.com/2013/03/handling-files-using-powershell.html
Powershell - Create Database,Table and Storedprocedure using SMO - http://www.allaboutmssql.com/2013/03/powershell-create-databasetable-and.html
Powershell Command to get status of SQL Server services - http://www.allaboutmssql.com/2013/03/powershell-command-to-get-status-of-sql.html
Using Powershell commands inside SQL Agent Jobs - http://www.allaboutmssql.com/2013/03/using-powershell-commands-inside-sql.html
Execute Powershell Commands inside StoredProcedure - http://www.allaboutmssql.com/2013/03/executing-powershell-commands-inside.html
SQL Server Reporting Services
SSRS (Matrix) - How to Repeat Headers on Each Page and Keep Headers Fixed while Scrolling
http://social.technet.microsoft.com/wiki/contents/articles/19505.ssrs-matrix-how-to-repeat-headers-on-each-page-and-keep-headers-fixed-while-scrolling.aspx
SSRS - No data message for report items
http://www.allaboutmssql.com/2013/08/ssrs-no-data-message-for-report-items.html
SSRS - How to display table after clicking on chart -
http://www.allaboutmssql.com/2013/08/ssrs-how-to-display-table-after.html
SSRS - How to repeat headers on each page
http://social.technet.microsoft.com/wiki/contents/articles/19398.ssrs-how-to-repeat-headers-on-each-page.aspx
SSRS - How to display multiple columns (header and value) horizontally stacked in one row cell - http://social.technet.microsoft.com/wiki/contents/articles/19363.ssrs-how-to-display-multiple-columns-header-and-value-horizontally-stacked-in-one-row-cell.aspx
SSRS - How to set Column Visibility property for many columns based on Parameter value -
http://social.technet.microsoft.com/wiki/contents/articles/19333.ssrs-how-to-set-column-visibility-property-for-many-columns-based-on-parameter-value.aspx
SSRS - To group same row data with one column having varying data
- http://www.allaboutmssql.com/2013/08/ssrs-to-group-same-row-data-with-one.html
SSRS - How to add variables -
http://www.allaboutmssql.com/2013/08/ssrs-how-to-add-variables.html
SSRS - Example for Conditional formatting -
http://www.allaboutmssql.com/2013/08/ssrs-example-for-conditional-formatting.html
SSRS - How to add Custom Code and example for using Custom Code -
http://www.allaboutmssql.com/2013/08/ssrs-how-to-add-custom-code-and-example.html
SSRS - Example for Tablix with Sparkline / Bar Chart / Indicator -
http://www.allaboutmssql.com/2013/08/ssrs-example-for-tablix-with-sparkline.html
SSRS - Example for Lookup , LookUpSet and MultiLookup functions -
http://www.allaboutmssql.com/2013/08/ssrs-example-for-lookup-lookupset-and.html
SSRS - Stacked Column (bar) Chart -
http://www.allaboutmssql.com/2013/08/ssrs-stacked-column-bar-chart.html
SSRS - Chart with two Vertical (Y) axes - Primary and secondary Vertical axes -
http://www.allaboutmssql.com/2013/08/ssrs-chart-with-two-vertical-y-axes.html
SSRS - Multiple Sparklines chart -
http://www.allaboutmssql.com/2013/08/ssrs-multiple-sparklines-chart.html
SSRS - Bar chart with line -
http://www.allaboutmssql.com/2013/08/ssrs-bar-chart-with-line.html
SSRS - How to repeat headers for each group -
http://www.allaboutmssql.com/2013/08/ssrs-how-to-repeat-headers-for-each.html
SSRS - Multiple ways to split a string into multiple lines -
http://www.allaboutmssql.com/2013/07/ssrs-multiple-ways-to-split-string-into.html
SSRS - Multi Font Color / Multi Font Size within Single Field / Textbox
- http://www.allaboutmssql.com/2013/07/ssrs-multi-font-color-multi-font-size.html
SSRS - In Bar Charts , how to adjust the size of the bars -
http://www.allaboutmssql.com/2013/06/ssrs-in-bar-charts-how-to-adjust-size.html
SSRS - In Charts , how to sort labels on X - axis (Horizontal axis) -
http://www.allaboutmssql.com/2013/06/ssrs-in-charts-how-to-sort-labels-on-x.html
SSRS - In Charts , how to display all labels on the X-axis (Horizontal axis) -
http://www.allaboutmssql.com/2013/06/ssrs-in-charts-how-to-display-all.html
SSRS - [rsRuntimeErrorInExpression] The Value expression for the textrun ‘Textbox1.Paragraphs[0].TextRuns[0]’ contains an error: Argument 'Month' is not a valid value - http://www.allaboutmssql.com/2013/05/ssrs-rsruntimeerrorinexpression-value.html
SSRS - Examples for using report functions in expressions - http://www.allaboutmssql.com/2013/04/ssrs-examples-for-using-report.html
SQL Server Reporting Services - Example for creating report - http://www.allaboutmssql.com/2012/08/sql-server-reporting-services-example.html
SQL Server Reporting Services - Example for Subreport and Drill-down report - http://www.allaboutmssql.com/2012/09/sql-server-reporting-services-example.html
SSRS - IsNothing - Decision Function - http://www.allaboutmssql.com/2013/01/ssrs-isnothing-decision-function.html
SSRS - IsMissing - Visibility Function - http://www.allaboutmssql.com/2013/01/ssrs-ismissing-visibility-function.html
SQL Server Reporting Services - Lookup Expression http://www.allaboutmssql.com/2012/09/ssrs-lookup-expression.html
SSRS - Report Deployment - http://www.allaboutmssql.com/2013/02/ssrs-report-deployment.html
SQL Server Reporting Services - DATAFILE(rdl.data) - http://www.allaboutmssql.com/2013/03/sql-server-reporting-services.html
Passing comma separated values (SSRS - multivalued parameter) as input to the stored procedure -
http://social.technet.microsoft.com/wiki/contents/articles/17104.passing-comma-separated-values-ssrs-multivalued-parameter-as-input-to-the-stored-procedure.aspx
http://social.technet.microsoft.com/wiki/contents/articles/19505.ssrs-matrix-how-to-repeat-headers-on-each-page-and-keep-headers-fixed-while-scrolling.aspx
SSRS - No data message for report items
http://www.allaboutmssql.com/2013/08/ssrs-no-data-message-for-report-items.html
SSRS - How to display table after clicking on chart -
http://www.allaboutmssql.com/2013/08/ssrs-how-to-display-table-after.html
SSRS - How to repeat headers on each page
http://social.technet.microsoft.com/wiki/contents/articles/19398.ssrs-how-to-repeat-headers-on-each-page.aspx
SSRS - How to display multiple columns (header and value) horizontally stacked in one row cell - http://social.technet.microsoft.com/wiki/contents/articles/19363.ssrs-how-to-display-multiple-columns-header-and-value-horizontally-stacked-in-one-row-cell.aspx
SSRS - How to set Column Visibility property for many columns based on Parameter value -
http://social.technet.microsoft.com/wiki/contents/articles/19333.ssrs-how-to-set-column-visibility-property-for-many-columns-based-on-parameter-value.aspx
SSRS - To group same row data with one column having varying data
- http://www.allaboutmssql.com/2013/08/ssrs-to-group-same-row-data-with-one.html
SSRS - How to add variables -
http://www.allaboutmssql.com/2013/08/ssrs-how-to-add-variables.html
SSRS - Example for Conditional formatting -
http://www.allaboutmssql.com/2013/08/ssrs-example-for-conditional-formatting.html
SSRS - How to add Custom Code and example for using Custom Code -
http://www.allaboutmssql.com/2013/08/ssrs-how-to-add-custom-code-and-example.html
SSRS - Example for Tablix with Sparkline / Bar Chart / Indicator -
http://www.allaboutmssql.com/2013/08/ssrs-example-for-tablix-with-sparkline.html
SSRS - Example for Lookup , LookUpSet and MultiLookup functions -
http://www.allaboutmssql.com/2013/08/ssrs-example-for-lookup-lookupset-and.html
SSRS - Stacked Column (bar) Chart -
http://www.allaboutmssql.com/2013/08/ssrs-stacked-column-bar-chart.html
SSRS - Chart with two Vertical (Y) axes - Primary and secondary Vertical axes -
http://www.allaboutmssql.com/2013/08/ssrs-chart-with-two-vertical-y-axes.html
SSRS - Multiple Sparklines chart -
http://www.allaboutmssql.com/2013/08/ssrs-multiple-sparklines-chart.html
SSRS - Bar chart with line -
http://www.allaboutmssql.com/2013/08/ssrs-bar-chart-with-line.html
SSRS - How to repeat headers for each group -
http://www.allaboutmssql.com/2013/08/ssrs-how-to-repeat-headers-for-each.html
SSRS - Multiple ways to split a string into multiple lines -
http://www.allaboutmssql.com/2013/07/ssrs-multiple-ways-to-split-string-into.html
SSRS - Multi Font Color / Multi Font Size within Single Field / Textbox
- http://www.allaboutmssql.com/2013/07/ssrs-multi-font-color-multi-font-size.html
SSRS - In Bar Charts , how to adjust the size of the bars -
http://www.allaboutmssql.com/2013/06/ssrs-in-bar-charts-how-to-adjust-size.html
SSRS - In Charts , how to sort labels on X - axis (Horizontal axis) -
http://www.allaboutmssql.com/2013/06/ssrs-in-charts-how-to-sort-labels-on-x.html
SSRS - In Charts , how to display all labels on the X-axis (Horizontal axis) -
http://www.allaboutmssql.com/2013/06/ssrs-in-charts-how-to-display-all.html
SSRS - [rsRuntimeErrorInExpression] The Value expression for the textrun ‘Textbox1.Paragraphs[0].TextRuns[0]’ contains an error: Argument 'Month' is not a valid value - http://www.allaboutmssql.com/2013/05/ssrs-rsruntimeerrorinexpression-value.html
SSRS - Examples for using report functions in expressions - http://www.allaboutmssql.com/2013/04/ssrs-examples-for-using-report.html
SQL Server Reporting Services - Example for creating report - http://www.allaboutmssql.com/2012/08/sql-server-reporting-services-example.html
SQL Server Reporting Services - Example for Subreport and Drill-down report - http://www.allaboutmssql.com/2012/09/sql-server-reporting-services-example.html
SSRS - IsNothing - Decision Function - http://www.allaboutmssql.com/2013/01/ssrs-isnothing-decision-function.html
SSRS - IsMissing - Visibility Function - http://www.allaboutmssql.com/2013/01/ssrs-ismissing-visibility-function.html
SQL Server Reporting Services - Lookup Expression http://www.allaboutmssql.com/2012/09/ssrs-lookup-expression.html
SSRS - Report Deployment - http://www.allaboutmssql.com/2013/02/ssrs-report-deployment.html
SQL Server Reporting Services - DATAFILE(rdl.data) - http://www.allaboutmssql.com/2013/03/sql-server-reporting-services.html
Passing comma separated values (SSRS - multivalued parameter) as input to the stored procedure -
http://social.technet.microsoft.com/wiki/contents/articles/17104.passing-comma-separated-values-ssrs-multivalued-parameter-as-input-to-the-stored-procedure.aspx
SQL Server Integration Services
SSIS - Extract filename from file path using TOKEN and TOKENCOUNT -
http://www.allaboutmssql.com/2013/08/ssis-extract-filename-from-file-path.html
SSIS - Shred data from XML file in folder into columns of a table -
http://www.allaboutmssql.com/2013/08/ssis-shred-data-from-xml-file-in-folder.html
SSIS - Capture Filenames while looping through multiple files inside folder - http://www.allaboutmssql.com/2013/02/ssis-capture-filenames-while-looping.html
SQL Server Integration services - Rename and move files from source folder to destination folder - http://www.allaboutmssql.com/2012/09/sql-server-integration-services-rename.html
SQL Server Integration Services - Logging in Packages - http://www.allaboutmssql.com/2012/09/sql-server-integration-services-logging.html
SQL Server Integration Services - Error handling for truncation error - http://www.allaboutmssql.com/2012/09/sql-server-integration-services-error.html
SQL Server Integration Services - DelayValidation property - http://www.allaboutmssql.com/2012/09/sql-server-integration-services.html
SSIS - CODEPOINT Function - http://www.allaboutmssql.com/2013/01/ssis-codepoint-function.html
SSIS -Solution for mixed data types problem while importing from excel - http://www.allaboutmssql.com/2012/08/ssis-solution-for-mixed-data-types.html
SSIS - Truncation error while exporting from excel to database - http://www.allaboutmssql.com/2012/07/ssis-truncation-error-while-exporting.html
SQL Server Integration Services - Error codes,Error symbolic names and Error messages - http://www.allaboutmssql.com/2012/09/sql-server-integration-services-error_10.html
Migrating DTS Packages to Integration Services - http://www.allaboutmssql.com/2012/04/migrating-dts-packages-to-integration.html
SQL Server Integration Services - ForceExecutionResult - http://www.allaboutmssql.com/2013/02/sql-server-integration-services.html
SSIS - Execute SQL Task - Result Set and Parameter Mapping
http://www.allaboutmssql.com/2013/04/ssis-execute-sql-task-result-set-and.html
SSIS - How to Add Missing Control Flow Items / Data Flow Items to the SSIS Toolbox
- http://www.allaboutmssql.com/2013/07/ssis-how-to-add-missing-control-flow.html
SSIS - Move Folder from one Drive to Another Drive Using File System Task
- http://www.allaboutmssql.com/2013/07/ssis-move-folder-from-one-drive-to.html
http://www.allaboutmssql.com/2013/08/ssis-extract-filename-from-file-path.html
SSIS - Shred data from XML file in folder into columns of a table -
http://www.allaboutmssql.com/2013/08/ssis-shred-data-from-xml-file-in-folder.html
SSIS - Capture Filenames while looping through multiple files inside folder - http://www.allaboutmssql.com/2013/02/ssis-capture-filenames-while-looping.html
SQL Server Integration services - Rename and move files from source folder to destination folder - http://www.allaboutmssql.com/2012/09/sql-server-integration-services-rename.html
SQL Server Integration Services - Logging in Packages - http://www.allaboutmssql.com/2012/09/sql-server-integration-services-logging.html
SQL Server Integration Services - Error handling for truncation error - http://www.allaboutmssql.com/2012/09/sql-server-integration-services-error.html
SQL Server Integration Services - DelayValidation property - http://www.allaboutmssql.com/2012/09/sql-server-integration-services.html
SSIS - CODEPOINT Function - http://www.allaboutmssql.com/2013/01/ssis-codepoint-function.html
SSIS -Solution for mixed data types problem while importing from excel - http://www.allaboutmssql.com/2012/08/ssis-solution-for-mixed-data-types.html
SSIS - Truncation error while exporting from excel to database - http://www.allaboutmssql.com/2012/07/ssis-truncation-error-while-exporting.html
SQL Server Integration Services - Error codes,Error symbolic names and Error messages - http://www.allaboutmssql.com/2012/09/sql-server-integration-services-error_10.html
Migrating DTS Packages to Integration Services - http://www.allaboutmssql.com/2012/04/migrating-dts-packages-to-integration.html
SQL Server Integration Services - ForceExecutionResult - http://www.allaboutmssql.com/2013/02/sql-server-integration-services.html
SSIS - Execute SQL Task - Result Set and Parameter Mapping
http://www.allaboutmssql.com/2013/04/ssis-execute-sql-task-result-set-and.html
SSIS - How to Add Missing Control Flow Items / Data Flow Items to the SSIS Toolbox
- http://www.allaboutmssql.com/2013/07/ssis-how-to-add-missing-control-flow.html
SSIS - Move Folder from one Drive to Another Drive Using File System Task
- http://www.allaboutmssql.com/2013/07/ssis-move-folder-from-one-drive-to.html
log_reuse_wait_desc = replication, transaction log won't stop growing
SELECT name, log_reuse_wait_desc FROM sys.databases
--if the log_reuse_wait_desc is replication then remove it
EXEC sp_removedbreplication YourDatabaseName
SELECT name, log_reuse_wait_desc FROM sys.databases
-- log_reuse_wait_desc on database should be changed to "nothing" now. if yes do following steps
ALTER DATABASE YourDatabaseName SET RECOVERY SIMPLE
DBCC SHRINKFILE (N'Your Logical Log Name', 0, TRUNCATEONLY)
--Now My log file size drop from 18GB to 0MB
--after that you should reset you database recovery model to full if you need.
--if the log_reuse_wait_desc is replication then remove it
EXEC sp_removedbreplication YourDatabaseName
SELECT name, log_reuse_wait_desc FROM sys.databases
-- log_reuse_wait_desc on database should be changed to "nothing" now. if yes do following steps
ALTER DATABASE YourDatabaseName SET RECOVERY SIMPLE
DBCC SHRINKFILE (N'Your Logical Log Name', 0, TRUNCATEONLY)
--Now My log file size drop from 18GB to 0MB
--after that you should reset you database recovery model to full if you need.
Size of the Transaction Log Increasing and cannot be truncated or Shrinked due to Snapshot Replication.
There
can be many reasons for the size of Transaction Log growing large for a
sql server database such as waiting on checkpoint, backups in Full
recovery model, active long running transaction.
The
simplest and the smartest way to determine the cause of the Transaction
Log in sql server 2005 is with the use of columns log_reuse_wait,
log_reuse_wait_desc in sys.databases view in Sql Server 2005 and 2008.
So we fire the following query to find the cause of the Transaction Log growth and observe the following
select log_reuse_wait_desc,name from sys.databases
log_reuse_wait_desc name
------------------------------------------------------------ -------------
REPLICATION test
And to
our surprise the log_reuse_wait_desc column reflects REPLICATION for a
particular database which has snapshot replication configured on it.
So we
conclude the Log growth is caused due to Snapshot Replication which is
kind of ironical since Snapshot Replication does not use Transaction
logs to replicate data to the remote site.
So to
confirm this we fire the DBCC OPENTRAN which gives the undistributed LSN
for the Transaction log and we get an undistributed LSN value as shown
below
DBCC OPENTRAN(13)
Transaction information for database 'test’.
Replicated Transaction Information:
Oldest distributed LSN : (0:0:0)
Oldest non-distributed LSN : (43831:51:1)
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
So this
confirms that above undistributed transaction is causing the Log
Growth. But in Snapshot Replication the changes are replicated using
Snapshots and not using Transaction Logs.
We have
a Known issue with Snapshot Replication in Sql Server 2005 which causes
DDL changes on the tables which have SCHEMA CHANGES marked for
replication where in the DDL statements are marked for Replication in
Transaction log of the database but they are not unmarked when the
changes are actually propagated.
In order to confirm whether we are hitting the issue mentioned above we need to check whether that undistributed LSN ((43831:51:1) in above case)
provided in DBCC OPENTRAN output is pointing to DDL operations of type ALTER TABLE.
The
issue is yet to be fixed and hence the workaround to avoid the issue is
to either remove the REPLICATION OF SCHEMA CHANGES for the tables
involved in the replication
Or
Use the following commands after running Snapshot Agent and applying the Snapshot on the subscriber.
sp_repldone null, null, 0,0,1
Before
running the above command we need to ensure that SCHEMA changes are
actually being replicated in order to avoid any inconsistency
Note:
This
post should not be treated as the Microsoft’s Recommendation or
Resolution to the problem, it is only a workaround which worked in our
environment and so we would like to share it.
Troubleshooting SQL Server CPU Performance Issues
In this post I’ll discuss a general methodology
for troubleshooting CPU performance issues. I like applying
methodologies by default and I also like building efficiencies in how I
troubleshoot issues based on past experiences. Without a general
framework, it becomes too easy to miss the true root cause in the middle
of a crisis.
The steps I’ll describe in this post are as follows:- Define the problem
- Validate the current conditions
- Answer “Is it SQL Server”?
- Identify CPU consumers
- Match the pattern and resolve
Define the problem
First we need to scope the issue. When someone comes up to you and says they are seeing a CPU performance issue, this could mean any number of different things. So the first task is to understand what the nature of the CPU performance issue currently is.Some common categories include:
- Availability being impacted due to “pegged CPUs”. For example – all schedulers running at 100% across the board and throughput being stalled or significantly reduced.
- Degradation of performance due to “higher than normal” CPU usage. So we’re not pegged, but your CPUs are running at a higher percentage than is ordinary and presumably it is impacting performance.
- Another common category of CPU performance issue is the “winners and losers” scenario where workloads are competing against each other. Perhaps you have an OLTP workload that is encountering reduced throughput due to a parallel executing report query.
- Another problem might be the encountering of a tipping point – where the overall capacity and scalability limitations of your system are hit at a certain point.
Validate the current conditions
Whether the issue happened in the past or is happening right now, it is important to get as much background information about the system, workload and configurations as possible. If you’re using baselines and run-books, ideally you’re tracking much of this information already. If not, ask yourself how quickly you could get answers to these questions at 2AM in the middle of a crisis.The following sub-sections cover important data points that I’m typically interested in for a CPU-performance issue.
- How many sockets and cores?
- Is hyper-threading enabled?
- What is the processor model, architecture (32-bit/64-bit)?
- Is this a virtual guest?
- If so, you’re now also going to be interested in details about the host and the other virtual guests you’re sharing resources with.
- Are there any CPU-related settings in effect?
- For example, Hyper-V CPU
- How many vCPUs are allocated across guests?
- How many vCPUs does this guest have?
- Was the guest recently migrated to a new host prior to the issue?
- Max degree of parallelism setting
- Cost threshold for parallelism option
- Processor affinity setting
- Priority boost setting
- Max worker threads setting
- Lightweight pooling setting
- What is the power-option setting? (OS level, VM Host or BIOS controlled)
- High Performance, Balanced, Power Saving?
- Is it configured beyond the default settings?
- Do you see any unusual warnings or errors?
Physical server details
Virtual server details
Reserve, VMware CPU Reservation, Hyper-V CPU Relative Weight, and VMware CPU Shares.
SQL Server instance configuration settings
The first three configurations may require further discussion. There are rarely absolutes regarding these settings.
Regarding the last three settings, such as “priority boost”, if I see that they are at non-default values I’m definitely going to be pushing for more background information and history.
CPU power-option settings
Resource Governor configuration
I still find that it is rare to encounter customers using this feature at all, but it is easy to validate whether it is being used and will be worth it for the times that it is actually configured beyond the default.
SQL Server error log and Windows event logs
Why look in the error and event logs for a CPU issue? Sometimes upstream issues can cause downstream performance issues in SQL Server. You don’t want to waste time tuning a query or adding a new index when you’re upstream root-cause issue is a hardware component degradation issue.
Answer “Is it SQL Server?”
It sounds obvious when I ask it, but you really don’t want to spend a significant amount of time troubleshooting a high CPU issue in SQL Server if the culprit isn’t actually SQL Server.Instead, take a quick moment to check which process is consuming the most CPU. There are several options to choose from, including:
- Process: % User Time (user mode)
- Process: % Privileged Time (kernel mode)
- Task Manager
- Process Explorer
- Recent CPU information via sys.dm_os_ring_buffers or the system health session for the specific SQL Server instances running on the system
SELECT SERVERPROPERTY('processid') to get the PID and then associating it to Task Manager or Process Explorer.Once you’ve confirmed it is SQL Server, are you seeing high user time or privileged (kernel) time? Again this can be confirmed via Process: % Privileged Time (sqlservr object) and also Windows Task Manager or Process Explorer.
While high kernel time issues should be rare, they still require different troubleshooting paths than standard user time CPU troubleshooting issues. Some potential causes of high kernel time include faulty filter-drivers (anti-virus, encryption services), out-of-date or missing firmware updates and drivers, or defective I/O components.
Identify CPU consumers
Once you’ve validated which SQL Server instance is driving the user-time CPU usage on the system, there are plenty of pre-canned query examples out on the web that you could use.Below is a list of DMVs that people commonly use in various forms during a performance issue. I structured this in a Q&A format to help frame why you would want to access them.
- sys.dm_exec_requests
- sys.dm_exec_sql_text
- sys.dm_exec_sessions
- sys.dm_exec_connections
- sys.dm_exec_query_plan
- sys.dm_os_waiting_tasks
- sys.dm_exec_query_stats
- Aggregate by total_worker_time
- Define averages with execution_count
- If ad hoc workloads, you could group by query_hash
- Use the plan_handle with sys.dm_exec_query_plan to grab the plan
- sys.dm_os_tasks
- Ordered by session_id, request_id
- sys.dm_exec_query_plan
- Look at plan operators – but keep in mind this is just the estimated plan
- sys.dm_exec_query_stats
- Filter total_elapsed_time less than total_worker_time
- But note that this can be a false negative for blocking scenarios – where duration is inflated due to a wait on resource
What requests are executing right now and what is their status?
What is it executing?
Where is it from?
What is its estimated plan? (but be careful of shredding xml on an already-CPU-constrained system)
Who’s waiting on a resource and what are they waiting for?
Which queries have taken up the most CPU time since the last restart?
Is this query using parallelism?
Match the pattern and resolve
You’re probably laughing at this particular step – as this one can be the most involved (and is another reason why SQL Server professionals are gainfully employed). There are several different patterns and associated resolutions – so I’ll finish this post with a list of the more common CPU performance issue drivers that I’ve seen over the last few years:- High I/O operations (and in my experience this is the most common driver of CPU)
- Cardinality estimate issues (and associated poor query plan quality)
- Unexpected parallelism
- Excessive compilation / recompilation
- Calculation-intensive UDF calls, shredding operations
- Row-by-agonizing row operations
- Concurrent maintenance activities (e.g. UPDATE stats with FULLSCAN)
Summary
As with any methodology, there are boundaries for its utilization and areas where you are justified in improvising. Please note that I’m not suggesting the steps I described in this post be used as a rigid framework, but instead consider it to be a launch-point for your troubleshooting efforts. Even highly experienced SQL Server professionals can make rookie mistakes or be biased by their more recent troubleshooting experiences, so having a minimal methodology can help avoid troubleshooting the wrong issue.How to restore database using Litespeed backup file and TSQL command
Lite Speed is an third party tool to
compress SQL backup and mainly used for SQL 2000 & SQL 2005. SQL
backup produced by using the Lite speed tool cannot be used as a normal
backup to perform the restore operation. SQL backup generated by Lite
speed tool can only be restored by using the Lite Speed utility . There
are two ways of restoring a Lite Speed backup. One is to follow the GUI
mode and it will guide you through the restore process and the other is
to use the below script which can perform the restoration in a much
quicker and easier way.
exec master.dbo.xp_restore_database @database = N’databasename’ ,
@filename = N’Full path of the backup file’,
@filenumber = 1,
@with = N’STATS = 10′,
@with = N’MOVE N”LogicalFileNameOf MDF file” TO N”Destinationpath\Logicalfilename.mdf”’,
@with = N’MOVE N”LogicalFileNameOf LDF file” TO N”Destinationpath\Logicalfilename.ldf”’,
@affinity = 0,
@logging = 0
GO
Example :-
exec master.dbo.xp_restore_database @database = N’Test’ ,
@filename = N’Q:\Backup\Test_20130308.bak’,
@filenumber = 1,
@with = N’STATS = 10′,
@with = N’MOVE N”Test” TO N”M:\data\Test.mdf”’,
@with = N’MOVE N”Test_log” TO N”H:\logs\Test_log.ldf”’,
@affinity = 0,
@logging = 0
GO
exec master.dbo.xp_restore_database @database = N’databasename’ ,
@filename = N’Full path of the backup file’,
@filenumber = 1,
@with = N’STATS = 10′,
@with = N’MOVE N”LogicalFileNameOf MDF file” TO N”Destinationpath\Logicalfilename.mdf”’,
@with = N’MOVE N”LogicalFileNameOf LDF file” TO N”Destinationpath\Logicalfilename.ldf”’,
@affinity = 0,
@logging = 0
GO
Example :-
exec master.dbo.xp_restore_database @database = N’Test’ ,
@filename = N’Q:\Backup\Test_20130308.bak’,
@filenumber = 1,
@with = N’STATS = 10′,
@with = N’MOVE N”Test” TO N”M:\data\Test.mdf”’,
@with = N’MOVE N”Test_log” TO N”H:\logs\Test_log.ldf”’,
@affinity = 0,
@logging = 0
GO
How to move database files of a Mirrored SQL Server Database
Problem
As you may know, you cannot detach a mirrored database or bring it offline to move a data or log file from one drive to another drive. Moving a database file for a mirrored database is not the same as moving a normal database. Here I will show you the step by step process on how to move the data and/or log file(s) from one drive to another drive with minimum downtime.Solution
Moving database files can be done two ways; by detaching the database then moving the database file(s) to the target location and then attaching the database from the new location. The other option is to run an ALTER statement to change the file location in the system catalog view, bring the database offline, then copy the file(s) to the target location and bring the database online. With database mirroring enabled for the database, both options will fail because your database is mirrored. We can't detach the mirrored database, nor can we bring it OFFLINE.Here is step by step solution to reduce your downtime and move your database file from one location to another location for a mirrored database.
Steps
Step 1Check the database files location for all database files. Here we are going to move database "NASSP2".
sp_helpdb NASSP2

Step 2
Check the database mirroring configuration for your database. Run the below script to check the database mirroring status and its current partner name.
SELECT (SELECT DB_NAME(7)AS DBName), database_id, mirroring_state_desc, mirroring_role_desc, mirroring_partner_name, mirroring_partner_instance FROM sys.database_mirroring WHERE database_id=7

Step 3
If the database file size is big it will take some time to copy from one drive to another drive. So to over come this issue and minimize the downtime, we will failover our database from our principal server to its MIRROR server and route our application to the new principal server (earlier mirrored box) to bring the application online and run business as usual. Run the below command to failover this database.
ALTER DATABASE NASSP2 SET PARTNER FAILOVER

Now we can again check the database mirroring configuration to see the current mirroring state. Run the same script which we ran in step 2. This time the output is the same, except one column. Here mirroring_state_desc is MIRROR where earlier it was principal.

Step 5
As we saw in step 1, two database files are on the C: drive. Now we have to move these two database files from 'C:' to 'E\MSSQL2008\DATA' drive. First we need to run an ALTER DATABASE statement to change the file location in master database system catalog view. Make sure to run this ALTER statement for every file that needs to be moved to the new location.
ALTER DATABASE NASSP2 MODIFY FILE (NAME='NASSP2_System_Data', FILENAME='E:\MSSQL2008\DATA\nassp2_system_data.mdf') go ALTER DATABASE NASSP2 MODIFY FILE (NAME='NASSP2_log', FILENAME='E:\MSSQL2008\DATA\nassp2_log.ldf') go

Now, stop the SQL Server instance to copy the data and log file(s) to the target location. I used PowerShell to stop and start the services. You can use services.msc utility or SQL Server Configuration Manager as well.
STOP-SERVICE MSSQLSERVER –FORCE

GET-SERVICE MSSQLSERVER

Now copy both database files (nassp2_system_data.mdf and nassp2_log.ldf) to the new target location ('C' to 'E:\MSSQL2008\DATA').
Step 8
Once both files has been copied, start the SQL Server services.
START-SERVICE MSSQLSERVER

GET-SERVICE MSSQLSERVER

Once SQL Server has started, failback your database from current principal to your primary box. Run step 1 again to check the location of the files and run step 2 again to check the mirroring status.

Next Steps
- Learn more database mirroring Database Mirroring Articles
SQL Server 2008 Management Data Warehouse
http://msdn.microsoft.com/en-us/library/dd939169%28v=sql.100%29.aspx
How to recover views, stored procedures, functions, and triggers: ApexSQL Log vs fn_dblog function
Regardless of precautions taken to
protect your SQL Server, accidents may still occur, causing serious
consequences, such as are data and objects loss. We will now analyze two
possible ways to recover SQL objects (views, stored procedures,
functions, and triggers) lost to accidental DROP statement use
The first way to recover dropped SQL objects is to use the undocumented
SQL Server fn_dblog function, which reads online database transaction
logs, and can provide information about the objects. More precisely, the
function can help in the following cases:
- for the database in full recovery model – if the transaction log wasn’t truncated after the object had been dropped
- for the database in simple recovery model – if the transaction log is intact (not overwritten by newer entries)
What steps need to be undertaken to recover a dropped object via the
fn_dblog function? The procedure is the same for all objects. Shown
below is the example for stored procedures:
- Execute the fn_dblog function
SELECT * FROM sys.fn_dblog(NULL, NULL);
The resulting table contains complete database transaction log data, divided in 129 columns - To
narrow down the results to the ones representing dropped objects,
execute the following SQL script, using “DROPOBJ” as the value for the
transaction name column:
SELECT * FROM sys.fn_dblog(NULL, NULL) WHERE [transaction name] IN ('DROPOBJ');
As you can see, we still have 129 columns, with no human-readable information whatsoeverTo translate the columns, you need to be familiar with the format, status bits, and their total number, and with some other characteristics beside. Unfortunately, no official documentation is available for this function, which makes the task a bit trickierThe following columns contain the information about the objects affected by the committed transaction: RowLog Contents 0, RowLog Contents 1, RowLog Contents 2, RowLog Contents 3, and RowLog Contents 4Row data is stored in different columns, based on the operation type. To see the exact required information using the fn_dblog function, you need to know the column content for each transaction type - Finally,
to get the CREATE PROCEDURE script, in order to re-create dropped
procedure, the following complex SQL script needs to be executed
SELECT CONVERT(varchar(max), SUBSTRING([RowLog Contents 0], 33, LEN([RowLog Contents 0]))) AS Script FROM fn_dblog(NULL, NULL) WHERE Operation = 'LOP_DELETE_ROWS' AND Context = 'LCX_MARK_AS_GHOST' AND AllocUnitName = 'sys.sysobjvalues.clst' AND [TRANSACTION ID] IN (SELECT DISTINCT [TRANSACTION ID] FROM sys.fn_dblog(NULL, NULL) WHERE Context IN ('LCX_NULL') AND Operation IN ('LOP_BEGIN_XACT') AND [Transaction Name] = 'DROPOBJ' AND CONVERT(nvarchar(11), [Begin Time]) BETWEEN '2013/07/31' AND '2013/08/1') AND SUBSTRING([RowLog Contents 0], 33, LEN([RowLog Contents 0])) <> 0; GO
As you can see, the script finds all related transactions, using the user-specified time frame for narrowing down the search, and converting hexadecimal values into readable textThe fn_dblog function is a powerful one, but it has limitations. For example, reading transaction log records for object structure changes usually involves the reconstruction of several system tables’ states, while only the active portion of the online transaction log is being read



As you can see from the examples provided above, this method is quite
complex. There is another way to perform the recovery, however. You may
use ApexSQL Log, a SQL Server recovery tool capable of reading transaction log data and recovering lost SQL objects to their original state by rolling back transactions
Let’s say there was a stored procedure named AUDIT_prc_AggregateReport
in the AdventureWorks2012 database that was dropped by a DROP PROCEDURE
statement
To recover the dropped procedure using ApexSQL Log:
- Connect to the AdventureWorks2012 database
- Add transaction log backups and/or detached transaction logs containing the data required to create the full chain and provide all transactions up to the point in time when the procedure was dropped. Use the Transaction logs tab to perform the operation
- Using the Database backups tab provide the full database backup to be used as the starting point from which the full chain of transactions will start
- Use the Filter tab and the Time range section to specify the target point in time for the recovery process (the time frame when the procedure was dropped). This will narrow down the search and speed up the reading process
- Finally, use the Operations filter to narrow down the search to the DROP PROCEDURE statements only. To do this, deselect all DML and DDL operations except DROP PROCEDURE. For other dropped objects (views, stored procedures, functions, and triggers), an appropriate option should be selected instead
- When everything has been set, use the Open button to start the reading process
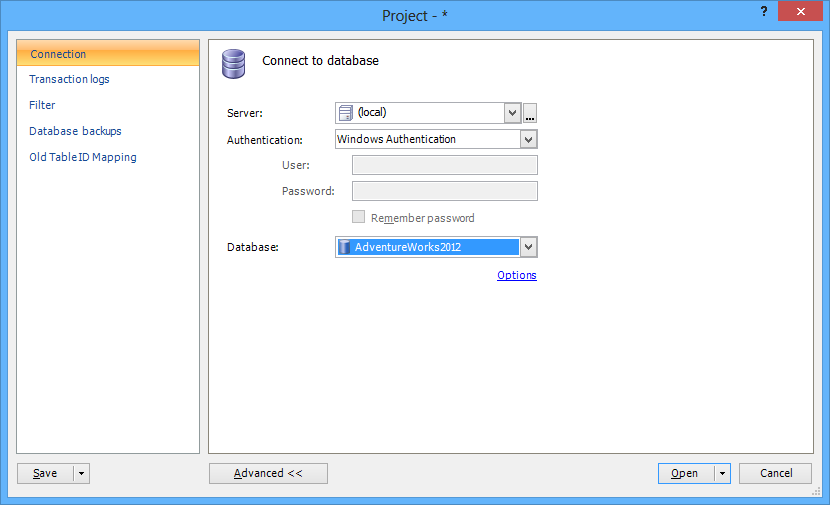
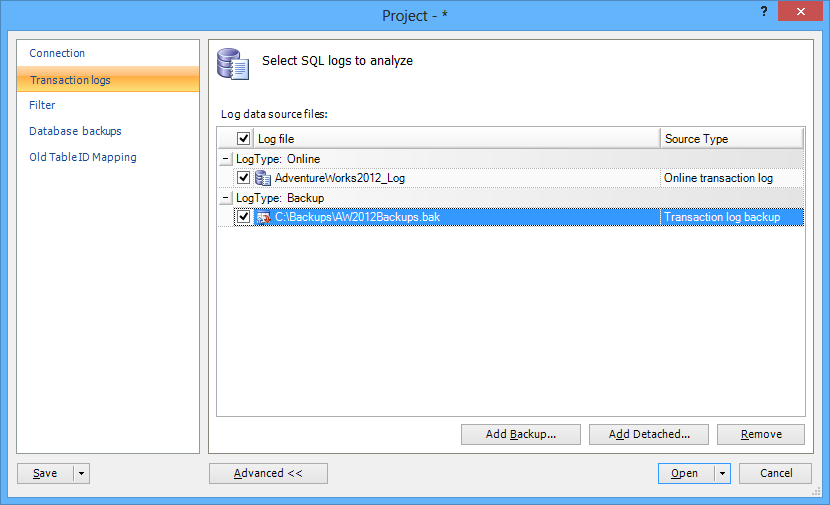
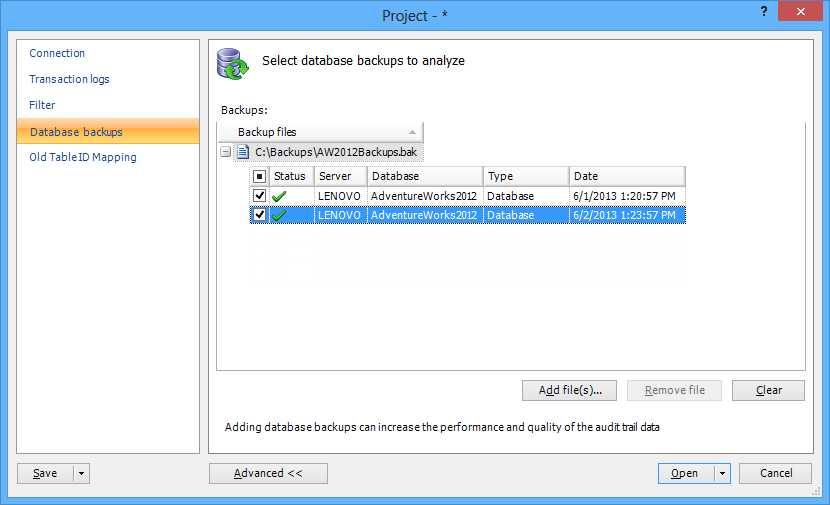
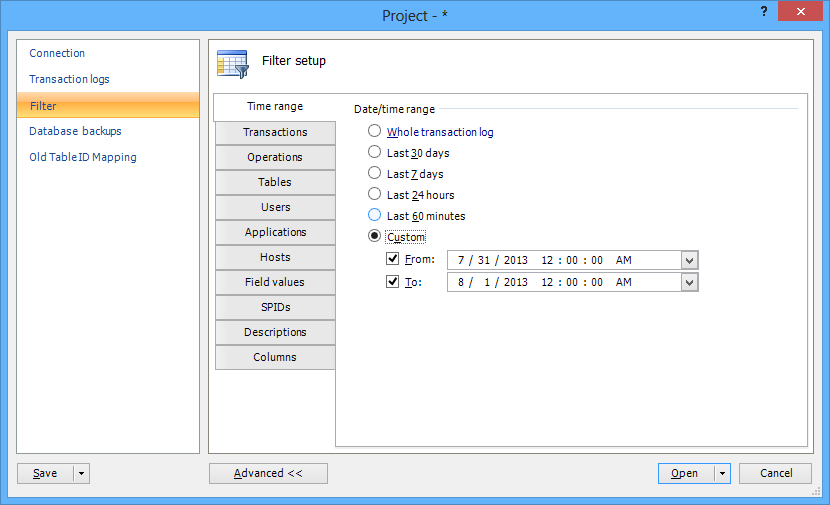
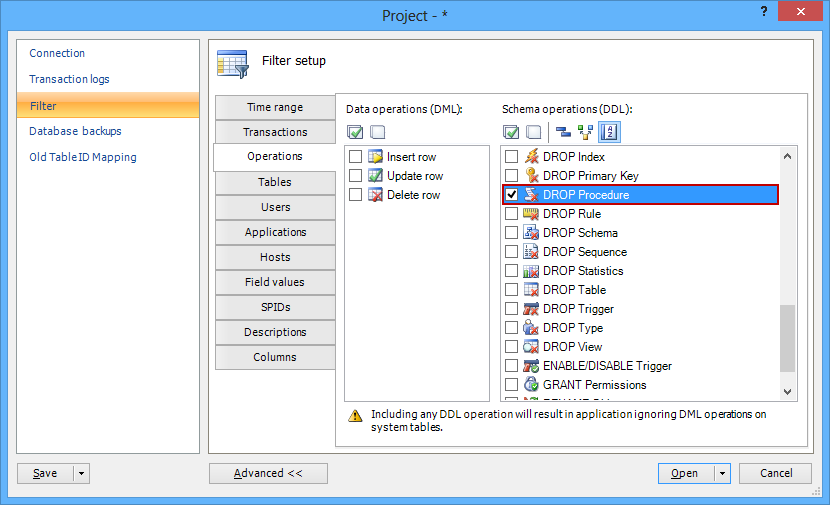
When the process has finished reading, the main grid will show the
transaction that can be rolled back, in order to recover the dropped
procedure

Finally, to perform the recovery, right-click the selected row, and choose the Create undo script option from the context menu. This will open the Undo script dialog containing the SQL script, which may be either executed immediately or saved for later use

Unlike the fn_dblog function, ApexSQL Log offers
a simple point-and-click recovery technique, which doesn’t call for
initial knowledge of SQL scripting and transaction log structure.
Furthermore, ApexSQL Log is
capable of reading the information stored in both online and
transaction log backups, which further simplifies the recovery procedure
Extended Events - SQL Errors
This script creates an Extended Events Session (XEvent) to capture SQL errors. Very useful to detect the object and the statement that is raising the error.
The first part creates the session and the second one is to retrieve the errors that are been raising.
IMPORTANT: This is a template so make sure you enter the proper values (Path and session name)
The first part creates the session and the second one is to retrieve the errors that are been raising.
IMPORTANT: This is a template so make sure you enter the proper values (Path and session name)
GO
-- Create XEvents
Session
exec master.dbo.xp_cmdshell 'Dir "<
XEvents_Folder,varchar(1000),C:\XEvents_output\xEvent_Target >*.*"'
CREATE EVENT SESSION < XEvents_Session_Name,varchar(1000),sql_text_and_errors >
ON SERVER
ADD EVENT sqlserver.error_reported
(
-- ACTION(
sqlserver.tsql_stack )
ACTION (sqlserver.tsql_stack,
sqlserver.sql_text,
sqlserver.database_id,
sqlserver.username,
sqlserver.client_app_name, sqlserver.client_hostname)
WHERE
((
[error] <> 2528 -- DBCC
execution completed...
AND [error] <> 3014 -- BACKUP LOG successfully processed ...
AND [error] <> 4035 -- Processed 0 pages for database ...
AND [error] <> 5701 -- Changed database context to ,,,
AND [error] <> 5703 -- Changed language setting to ...
AND [error] <> 18265
-- Log was backed up. ...
AND [error] <> 14205
-- (unknown)
AND [error] <> 14213 -- Core Job
Details:
AND [error] <> 14214 -- Job
Steps:
AND [error] <> 14215 -- Job
Schedules:
AND [error] <> 14216 -- Job
Target Servers:
AND [error] <> 14549
-- (Description not requested.)
AND [error] <> 14558
-- (encrypted command)
AND [error] <> 14559
-- (append output file)
AND [error] <> 14560
-- (include results in history)
AND [error] <> 14561
-- (normal)
AND [error] <> 14562
-- (quit with success)
AND [error] <> 14563
-- (quit with failure)
AND [error] <> 14564
-- (goto next step)
AND [error] <> 14565
-- (goto step)
AND [error] <> 14566
-- (idle)
AND [error] <> 14567
-- (below normal)
AND [error] <> 14568
-- (above normal)
AND [error] <> 14569
-- (time critical)
AND [error] <> 14570
-- (Job outcome)
AND [error] <> 14635
-- Mail queued.
AND [error] <> 14638 --
Activation successful.
AND [error] <= 50000 -- Exclude User
Errors
)))
----------------------------------------------------------------------------------
-- Target File Mode
-- ****** Make sure you
have enough disk space - Also you must monitor the disk while the session is
running ******
ADD TARGET package0.asynchronous_file_target
(SET filename='<
XEvents_Folder,varchar(1000),C:\XEvents_output\xEvent_Target >'
,max_file_size=4000
)
----------------------------------------------------------------------------------
WITH
(
MAX_MEMORY =
4096KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 1 SECONDS,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = ON, -- Very important to get
the event in order later on
STARTUP_STATE = ON -- Note that we start on
);
----------------------------------------------------------------------------------------------
-- STEP: Start the
session & see which sessions are currently running
ALTER EVENT SESSION < XEvents_Session_Name,varchar(1000),sql_text_and_errors >
ON SERVER
STATE = START
GO
----------------------------------------------------------------------------------------------
-- STEP: Wait for
events to be recoredd
-- Ring Buffer Mode
SELECT
len(
target_data ) as
[Len Buffer]
FROM sys.dm_xe_session_targets st (nolock)
JOIN sys.dm_xe_sessions s (nolock) ON
s.address = st.event_session_address
WHERE
s.name
= ''
-- Target File Mode
exec master.dbo.xp_cmdshell 'Dir "<
XEvents_Folder,varchar(1000),C:\XEvents_output\xEvent_Target >*.*"'
GO
----------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------
--*********************************************************************************************
-----------------------------------------------------------------------------------------------
-- Retrieve XEvents
output
SET NOCOUNT ON
DECLARE
@outputfile varchar(500)='<
XEvents_Folder,varchar(1000),C:\XEvents_output\xEvent_Target >' -- !!!! Edit your custom path here
---------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------
-- Target File Mode
-- STEP: Get the Events
captured - Note that the session can be still running & this can be
repeated
IF (object_id( 'tempdb..#EventXML'
) IS NOT NULL) DROP TABLE #EventXML ;
DECLARE
@path NVARCHAR(260) = @outputfile+'*',
@mdpath NVARCHAR(260) = @outputfile+'*.xem',
@initial_file_name NVARCHAR(260) = NULL,
@initial_offset BIGINT = NULL
Select
Identity(int,1,1) as ID
,*
,cast
(
Replace(
E.event_data, char(3), '?'
) as xml
) as X
into #EventXML
FROM
master.sys.fn_xe_file_target_read_file (@path, @mdpath,
@initial_file_name, @initial_offset) E
----------------------------------------------------------------------------------------------
-- STEP: Shred the XML
for the above event types
IF (object_id( 'tempdb..#EventDetail'
) IS NOT NULL) DROP TABLE
#EventDetail ;
--Shred the XML
SELECT
node.value('./@timestamp', 'datetime') AS event_time,
node.value('./@name', 'varchar(4000)') AS event_name
,CASE node.value('./@name', 'varchar(4000)')
WHEN 'error_reported' THEN
node.value('(./data)[5]', 'varchar(4000)')
ELSE NULL
END AS [Message]
,CASE node.value('./@name', 'varchar(4000)')
WHEN 'error_reported' THEN
node.value('(./data)[1]', 'int')
ELSE NULL
END AS Error_Value
,CASE node.value('./@name', 'varchar(4000)')
WHEN 'error_reported' THEN
node.value('(./action)[7]', 'varchar(50)')
WHEN 'sp_statement_completed' THEN
node.value('(./action)[1]', 'varchar(50)')
ELSE node.value('(./action)[2]', 'varchar(50)')
END AS activity_guid
,cast(null as
int) as activity_sequence
,cast
(
CASE
WHEN node.value('./@name', 'varchar(4000)') IN ('sp_statement_starting', 'error_reported') THEN node.value('(./action)[1]', 'varchar(4000)')
ELSE NULL
END
as xml
) AS TSql_stack
,CASE node.value('./@name', 'varchar(4000)')
WHEN 'error_reported' THEN
node.value('(./action)[2]', 'varchar(4000)')
ELSE NULL
END AS SQL_Text
,CASE node.value('./@name', 'varchar(4000)')
WHEN 'error_reported' THEN
node.value('(./action)[3]', 'int')
ELSE NULL
END AS [DBID]
,cast(null as
int) as ObjectID
,CASE node.value('./@name', 'varchar(4000)')
WHEN 'error_reported' THEN
node.value('(./action)[4]', 'varchar(256)')
ELSE NULL
END AS [UserName]
,CASE node.value('./@name', 'varchar(4000)')
WHEN 'error_reported' THEN
node.value('(./action)[5]', 'varchar(256)')
ELSE NULL
END AS [AppName]
,CASE node.value('./@name', 'varchar(4000)')
WHEN 'error_reported' THEN
node.value('(./action)[6]', 'varchar(256)')
ELSE NULL
END AS [HostName]
,cast(null as
varbinary(1000) ) AS handle
,cast( null
as int) as offsetstart
,cast( null
as int) as offsetend
,cast(null as
varchar(4000) ) as Statement_Text
,cast( null
as sysname) as [DatabaseName]
,cast(null as
sysname) as [ObjectName]
,#EventXML.*
INTO
#EventDetail
FROM #EventXML
CROSS APPLY #EventXML.x.nodes('//event') n (node)
-- Select count(*) as
Events FROM #EventDetail
-- SELECT * FROM
#EventDetail
----------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------
-- STEP: Separate
Activity GUID from Sequence number - for sorting later on (should be combined w
above step)
Update D Set
activity_sequence = CONVERT(int, RIGHT(activity_guid, LEN(activity_guid) - 37))
,activity_guid
= CONVERT(uniqueidentifier, LEFT(activity_guid, 36))
FROM
#EventDetail D
-- SELECT * FROM
#EventDetail
----------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------
-- STEP: Extract
handles & Offsets (should be combined w above step)
--Get the SQL handles
Update D Set
Handle =
CONVERT(varbinary(1000), frame.node.value('@handle', 'varchar(1000)'), 1)
,offsetstart
= frame.node.value('@offsetStart', 'int')
,offsetend = frame.node.value('@offsetEnd', 'int')
FROM
#EventDetail D
OUTER APPLY D.tsql_stack.nodes('(/frame)[1]') frame (node)
-- SELECT * FROM
#EventDetail
----------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------
-- STEP: For each
handle, grab the SQL text (should be combined w single table above)
Update D Set
statement_text = Left( SUBSTRING(t.text, (IsNull(offsetstart,0)/2) + 1, ((case when IsNull(offsetend,0) > 0 then offsetend
else 2*IsNull(len(t.text),0) end - IsNull(offsetstart,0))/2) + 1) , 4000 )
,[DatabaseName]
= DB.Name
,objectid = T.objectid
FROM
#EventDetail D
cross APPLY sys.dm_exec_sql_text(D.handle) t
inner join master.sys.sysdatabases db (nolock) on db.dbid = D.dbid
-- select count(*) as
Results from #EventDetail
----------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------
-- Dereference
ObjectName
set nocount on
Declare @Tbl table ( Name sysname )
Declare @Stmt varchar(max)
Declare @DBName sysname
Declare
@ObjectName sysname
Declare @ObjectId int
DECLARE curObj CURSOR
FOR Select Distinct
[DatabaseName], objectid from #EventDetail where
ObjectName is null
and [DatabaseName] is
not null
OPEN curObj
WHILE (1=1)
BEGIN
FETCH NEXT FROM curObj INTO @DBName,
@ObjectId
IF (@@fetch_status <> 0)
break
Set @Stmt
= 'select Name from '
+ @DBName + '.sys.sysobjects (nolock) where id = ' + convert( varchar(10), @ObjectId)
Insert into @Tbl
exec ( @Stmt )
Set
@ObjectName = null
Select
@ObjectName = Name from
@Tbl
Delete from @Tbl
Update
#EventDetail Set ObjectName = @ObjectName where
[DatabaseName] = @DBName and objectid =
@ObjectId
END
CLOSE curObj
DEALLOCATE curObj
set nocount off
-- Show Details
Select
getdate() as now
,@@servername as Server_Name
,count(*) as
[# of Errors]
,[message]
,[DatabaseName]
,[ObjectName]
,min([statement_text]) as
Ex1_statement_text
,max([statement_text]) as
Ex2_statement_text
,min([SQL_Text])
as Ex1_SQL_Text
,max([SQL_Text])
as Ex2_SQL_Text
--,[event_name]
,min([event_time]) as Min_event_time
,max([event_time]) as Max_event_time
,[Error_Value]
,[AppName]
,min([HostName])
as Ex1_HostName
,max([HostName])
as Ex2_HostName
,min([UserName])
as Ex1_UserName
,max([UserName])
as Ex2_UserName
from
#EventDetail
where
IsNull([Error_Value],0) < 50000
group by
[DatabaseName]
,[ObjectName]
,[event_name]
,[Error_Value]
,[message]
,[AppName]
order by
[# of Errors] desc
GO
Subscribe to:
Comments (Atom)